Job Processing System – Architecture Overview
Introduction
The Job Processing System is a modular and policy-driven infrastructure for processing, assigning, and executing tasks within an organization. It integrates approval mechanisms, dynamic agent selection strategies, task prioritization, and configuration management. The system is built to support both automated and human-intervened execution flows, providing flexibility, scalability, and extensibility.
This document outlines the architecture and flow of the system as implemented in the provided design.
High-Level Flow
-
Task Initiation Tasks are submitted for processing via the internal API. Before a task is accepted, a DSL-based approval mechanism may be invoked.
-
Task Approval and Insertion If approved, the task is inserted into the task queue and stored in the task database. The task's status is updated accordingly.
-
Priority Queue Management All tasks are pushed into a Redis-based internal priority queue. Tasks can be re-ordered by a DSL-based priority assigner or follow FCFS if prioritization is disabled.
-
Job Execution Flow Once a task is dequeued for execution, the job execution module pulls the current org configuration and determines the responsible agent using one of several resolution strategies.
-
Agent Resolution Strategies The system supports multiple agent selection methods:
-
Auction-based: Tasks are bid on by candidate agents via an auction DSL.
- Plan-and-retrieve: A DSL is used to evaluate candidate agents and select one based on dynamic factors.
-
Static assignment: The responsible agent is pre-defined in the org's configuration and validated against the candidate pool.
-
Agent Assignment and Dispatch Once an agent is selected, the task is assigned and updated in the database. The task is then published to the agent-specific NATS topic for execution.
-
Job Execution The agent receives the task and begins execution based on configuration and available resources. Optional validation and job parsing can be applied before execution begins.
Key Components
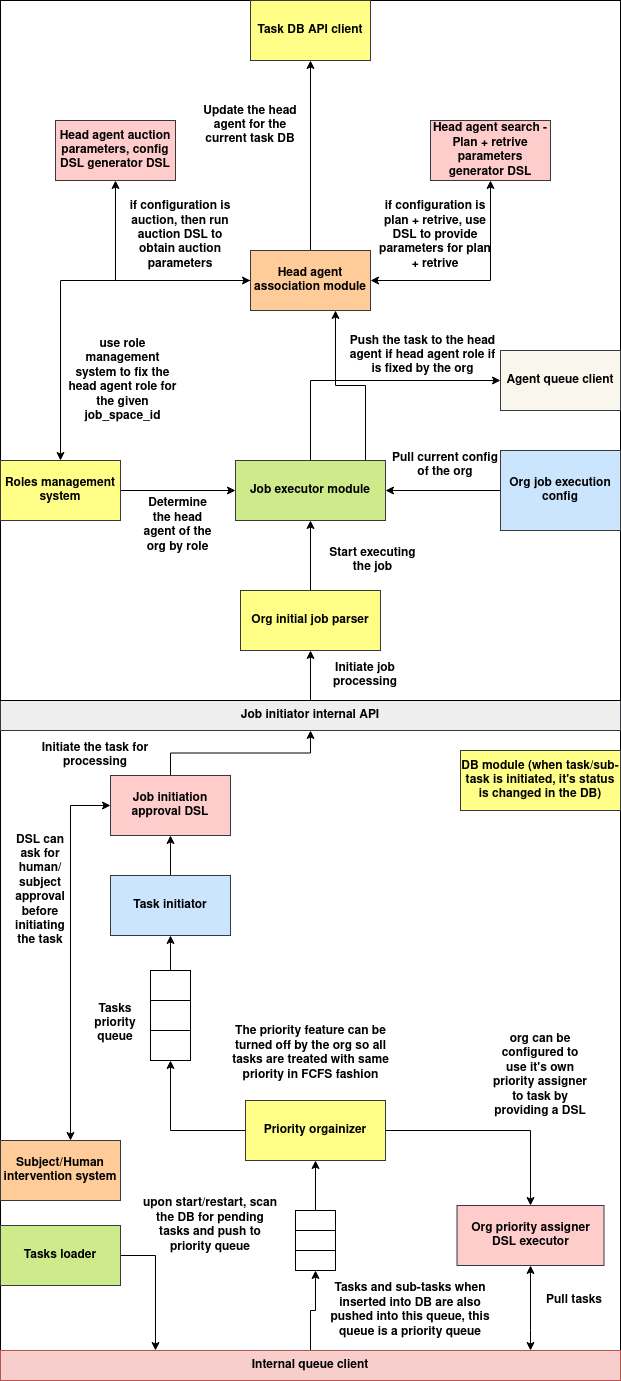
1. Task Initiator
Handles the receipt of new task submissions. Validates via a DSL if required and places approved tasks into the task priority queue.
2. Task Loader
On system restart, loads pending tasks from the database and re-queues them for processing.
3. Priority Organizer
Manages the task queue order. It can apply custom DSL-based prioritization or default to FCFS.
4. Job Executor Module
Central component that coordinates execution. It pulls org config, invokes the head agent association module, and starts job processing.
5. Head Agent Association Module
Determines the head agent to whom the task should be assigned. Supports multiple strategies:
- Auction DSL
- Plan-and-retrieve DSL
- Static mapping via role management
6. Agent Candidate Pool Resolver
Fetches eligible subjects based on role mappings and job-space ID, using external role and subject-role databases.
7. Agent Queue Client
Publishes the task to the selected agent’s message queue using NATS.
8. Org Execution Config Provider
Manages and retrieves configuration values per organization using Redis. Each configuration parameter is stored independently.
9. Org Initial Job Parser
Validates the structure and completeness of a task before execution.
Communication and Data Flow
- Redis: Used for internal task queues and organization-level config management.
- MongoDB: Stores task and sub-task entries.
- Flask APIs: Handle internal job/task operations and configuration updates.
- NATS: Used to deliver assigned tasks to agent-specific queues.
- External Role Management APIs: Queried to resolve eligible agent roles and subject mappings.
DSLs Used
The system uses multiple Domain-Specific Languages (DSLs) to externalize decision logic for validation, prioritization, and agent resolution. Each DSL is invoked at a specific stage of the job lifecycle and is configurable per organization.
| DSL Name | Trigger Stage | Input Parameters | Expected Output | Config Source |
|---|---|---|---|---|
| Job Initiation Approval DSL | Before accepting a task | task_id, goal, intent, submitter_subject_id, etc. |
{ "accepted": bool, "reason": str, ... } |
task.task_op_convertor_dsl_id or org config |
| Task Priority Assigner DSL | Before enqueueing into final queue | Task or sub-task fields | { "priority": int } |
task.task_behavior_dsl_map["priority_assigner_dsl_id"] or org config |
| Auction Input Generator DSL | Agent selection (auction strategy) | task_id, goal, intent, job_space_id, submitter_subject_id, etc. |
{ ... auction-specific parameters ... } |
task.task_behavior_dsl_map["auction_input_dsl_id"] or org config |
| Plan+Retrieve DSL | Agent selection (plan+retrieve) | Task data + list of candidate subject_ids |
{ "head_agent_subject_id": str } |
task.task_behavior_dsl_map["plan_retrieve_dsl_id"] or org config |
These DSLs are dynamically executable using the configured DSL engine and support both local and remote execution modes. Each organization can override the DSLs per task or globally configure them through the org config interface.
Certainly. Below is the structured documentation for the REST APIs used in the Job Processing System.
REST API Documentation
This section describes the internal REST APIs that enable task submission, configuration management, and role resolution in the job processing system.
1. Submit a Task
Endpoint: /internal/process-task
Method: POST
Description: Submit a task or sub-task for processing. The task goes through validation, head agent assignment, and queue dispatch.
Request Body
{
"type": "task", // or "sub_task" (sub_task currently not implemented)
"data": {
// Full TaskEntry or SubTaskEntry object
}
}
Response (Success)
{
"status": "assigned",
"subject_id": "subject-xyz"
}
Response (Failure)
{
"error": "No agent could be assigned"
}
2. Get Org Configuration Parameter
Endpoint: /org-config/<org_id>/<key>
Method: GET
Description: Retrieve a specific configuration value for the given organization.
Response (Success)
{
"success": true,
"key": "agent_resolution_strategy",
"value": "auction"
}
Response (Not Found)
{
"success": false,
"error": "Key 'agent_resolution_strategy' not found for org org-123"
}
3. Set Org Configuration Parameter
Endpoint: /org-config/<org_id>/<key>
Method: POST
Description: Set or update a configuration key-value pair for the given organization.
Request Body
{
"value": "plan+retrieve"
}
Response
{
"success": true
}
4. Query Role-to-Group Mapping
Endpoint: /role-group
Method: POST
Description: Query all roles that match the filter (e.g., role_type: "SCOUTING") using MongoDB-style syntax.
Request Body
{
"role_type": "SCOUTING",
"job_space_id": "space-001"
}
Response
{
"success": true,
"data": [
{
"role_id": "scout-1",
"role_type": "SCOUTING",
"group_ids": ["group-a"],
"job_space_id": "space-001"
}
]
}
5. Query Subject-to-Role Mapping
Endpoint: /subject-roles
Method: POST
Description: Query subject-role mappings based on one or more role IDs.
Request Body
{
"role_ids": { "$in": ["scout-1", "scout-2"] },
"job_space_id": "space-001"
}
Response
{
"success": true,
"data": [
{
"subject_id": "agent-a",
"role_ids": ["scout-1"],
"subject_type": "agent",
"job_space_id": "space-001"
}
]
}
Notes
- All APIs are internal-facing and should be protected accordingly.
- APIs return
200 OKfor successful responses and4xx/5xxfor errors. - Task submissions are synchronous in terms of acceptance but asynchronous in terms of actual execution.